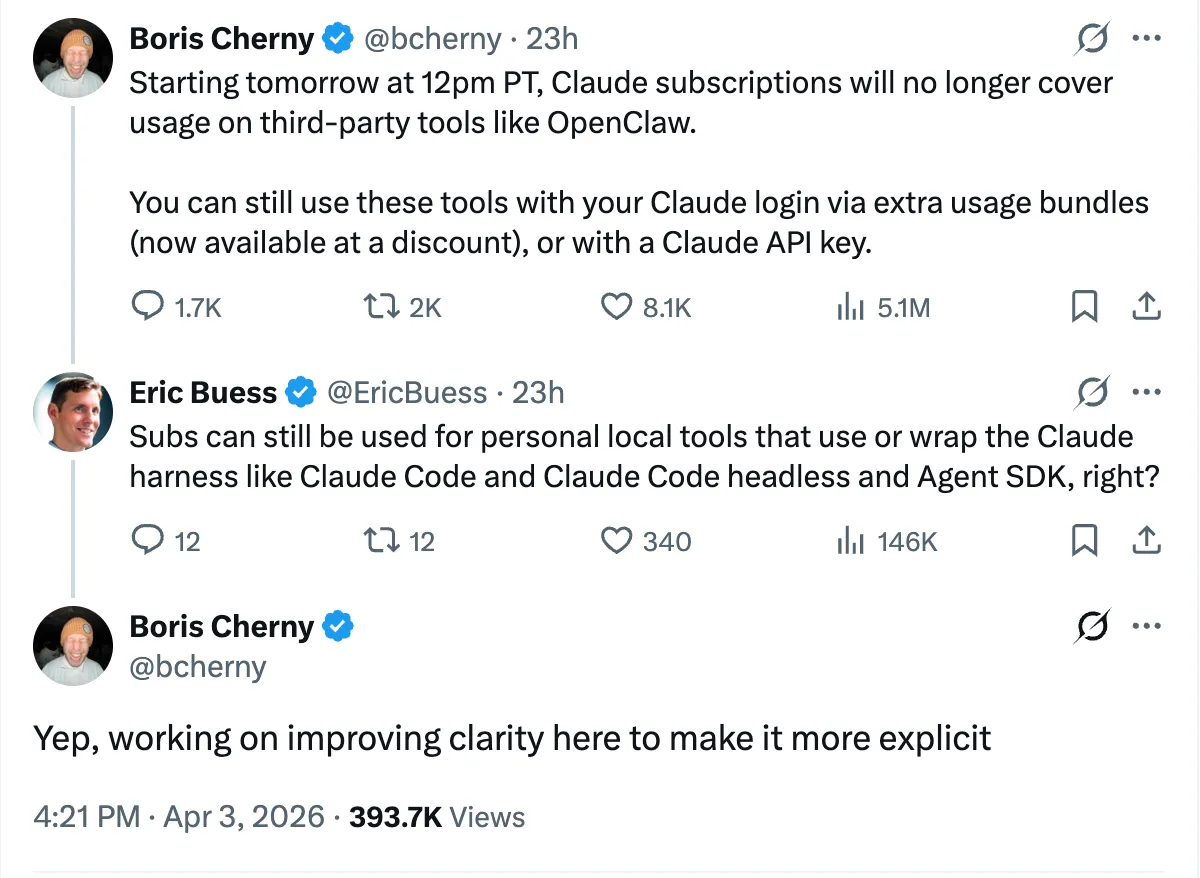
I was mid-plan when the Anthropic announcement dropped - Claude Code subscriptions would no longer cover third-party harnesses. Tools like OpenClaw, which run continuous automated builds on Claude’s infrastructure, now require separate pay-as-you-go billing. The subtext was straightforward: flat-rate pricing doesn’t survive automated systems that run 24/7.
My first question was whether eforge fell into the same bucket. Within hours, Boris Cherny - the creator of Claude Code - confirmed in an X reply that personal local tools wrapping the Claude Code harness, headless mode, and Agent SDK are still covered under subscriptions. eforge uses the Agent SDK to spin up Claude Code instances under my Max subscription - so it’s probably fine. For now.
But “probably fine” is doing a lot of work in that sentence. The clarification came from an X reply, not official documentation. Boris himself said he’s “working on improving clarity” - which means the clarity doesn’t exist yet. The policy that governs whether my primary development workflow keeps working is, at this moment, one person’s tweet. That’s its own kind of vendor risk, even when the answer is favorable.
This is why I added a second backend to eforge last week. Pi connects to over 15 LLM providers including local models. I built it as a vendor lock-in hedge. The Anthropic announcement didn’t break anything - but it confirmed that the hedge was the right call.
The three costs of a cheaper model
The conversation about model pricing usually stops at the sticker price - cost per million tokens. That’s the wrong number to optimize for. In an agentic build system, there are three distinct costs, and only one of them shows up on the invoice.
Per-token cost is what the provider charges. Opus is expensive. GPT 5.4 is cheaper. Local models like Google’s Gemma 4 are free. Right now the pool of models I actually trust for this work is small - Opus, Sonnet, GPT 5 - but as more cross that threshold, per-token price becomes the tiebreaker.
Correction overhead is the hidden multiplier. I ran the same eval build across Opus and GPT 5.4 this week - Opus completed it in about four minutes, GPT 5.4 in three and a half. I also tried Gemma 4 locally, not as a serious alternative but to see how eforge’s guardrails held up against a much smaller model. Despite roughly six times the token generation speed, it took over seven minutes - the speed advantage entirely consumed by rework. More correction passes, more review cycles, more back-and-forth before reaching a valid state. A model that’s cheaper per token but triggers more review cycles isn’t saving money. It’s hiding the cost in a different line item.
Build failure is the catastrophic case. Not just more expensive than expected - a total loss. With Opus and a well-written plan, I’ve rarely seen an eforge build fail because the model drifted too far during execution. The final validation pass recovers from minor issues, and the build lands. I had an hour-and-forty-five-minute Opus build yesterday that completed successfully - a large coordinated change across many files. The time didn’t matter. What mattered was that I handed it off, moved on to other planning work, and came back to a successful result.
The Gemma 4 experiment showed the extreme version of this - the same small eval succeeded once in 7 minutes, then failed the next attempt at 19 minutes. Same prompt, same eval, completely different outcomes. With Opus, a four-minute eval build lands every time, and so does a two-hour build. The confidence scales because the model holds coherence. That reliability gap is what eforge needs closed before smaller models become viable.
What the workflow actually requires
The way I work with eforge is simple: I plan carefully, I hand off, I move to planning the next thing. The build runs in the background. I trust it to succeed. That trust is the entire value of the system - it’s what lets me stay in the planning layer instead of dropping back into implementation mode. And the trust isn’t blind - it comes from two places: the quality of the model executing the build, and the quality of the plan I wrote before handing it off. Both matter. A great model with a sloppy plan will drift. A detailed plan with a weak model will still collapse. The combination is what makes the workflow reliable.
The moment builds start failing unpredictably, I’m pulled back into monitoring - and the “free” local model is actually costing me flow state.
This reframes what “model quality” means in a harness context. The question isn’t “can this model write decent code?” - it’s whether it can hold architectural coherence across a thirty-file build while an adversarial reviewer pushes back on every hunk, and do it reliably enough that I never think about whether it will land. That’s the difference between a model that demos well and a model that builds well. Most models can do the first. Only a handful of frontier models consistently do the second.
The dependency is real
eforge doesn’t need the best model. It needs a model above a quality floor - good enough that the adversarial reviewer is catching edge cases and style issues, not rewriting fundamentals. When the builder’s output is structurally sound, the review layer refines it. When the builder’s output drifts - wrong abstractions, misunderstood intent, conversational filler where precise code should be - the reviewer isn’t refining, it’s salvaging.
That floor isn’t fixed - it depends on the complexity of the build, the clarity of the plan, the number of files in play. But for the kind of work I do with eforge - large coordinated builds across many files - the floor is high. Right now, a small cluster of frontier models clear it: Opus, GPT 5, likely a couple of others. Before models at this level existed, the workflow wasn’t possible - not difficult or expensive, just not possible.
The pool is growing, but it’s still small. The idea of eforge is dependent on frontier intelligence in a way I can’t architect around. I can make the model swappable. I can’t make the methodology work with a model that isn’t good enough.
Building for a shift that’s visible but not here yet
That dependency is real, but it doesn’t have to mean locked into one provider.
The competitive dynamics are moving fast - Anthropic, OpenAI, Google, Meta, Mistral all racing on the same capabilities, each leap matched within months. That race drives per-token prices down and quality up simultaneously. What Opus costs today will buy something better in six months.
The architectural response is to make the model a swappable component. eforge’s Pi backend makes each agent role independently configurable, and the eval infrastructure is what makes it durable - if I can programmatically measure whether a model crosses the quality floor for each role, model selection becomes a config change backed by data, not a gut decision. The eval suite is where the durability lives, not the model it happens to evaluate.
Anthropic’s policy change is a nudge toward something that was going to happen anyway. Flat-rate subscriptions for automated agentic usage were a transitional artifact. The future is per-token pricing, and the question is whether competitive pressure drives those prices down fast enough that the workflow stays accessible.
I think it will. The trajectory from Gemma 2 to Gemma 4 is steep. A future 70B model tuned for sustained multi-file implementation could close the gap on the metrics that actually matter for this workflow. Local execution with enough unified memory would make the marginal cost of a build effectively zero.
The architecture needs to be ready for that moment. Provider-agnostic backends, per-agent model configuration, eval-driven quality gates - these decisions cost nothing if only one model is good enough today. They pay off the moment a second one crosses the floor. The planning layer is the same regardless - I wrote about that model-independence in The Flinch.
That’s the bet - not on any specific model, but on the market producing what the workflow needs at a price the workflow can sustain. I’d rather be ready to swap than stuck rewriting when the economics shift.